Difference between revisions of "Team:NCTU Formosa/Peptide Prediction"
| Line 510: | Line 510: | ||
<p> | <p> | ||
| − | A peptide that has higher ratio of potentially antifungal dipeptides will more likely to be an antifungal peptide, and vise versa. | + | A peptide that has higher ratio of potentially antifungal dipeptides will more likely to be an antifungal peptide, and vise versa. The propensity of each dipeptide will be converted to a weight score (dipeptide propensity score). |
</p> | </p> | ||
Revision as of 23:24, 1 November 2017










Overview

Our database, a new genesis for Artificial Intelligence, strengthens the power of large datasets by the antifungal peptide prediction system on the basis of SCM with other optimization. The antifungal characteristic can be evaluated and interpreted only by sequence analysis.
Furthermore, we integrated all the relative data to form a complete antifungal database to achieve the query function of hosts, pathogens, and corresponding peptides. Combining two together, a novel Parabase database achieving both new drug discovery and old drug repurposing for antifungal peptides is born.
Antifungal Prediction System
In order to evaluate peptide functions in a quicker and smarter way, we introduced SCM into making our antifungal peptide prediction system. With this applicable and interpretable tool, we are able to find potential target peptides in a large number of unknown peptides, making the best use of vast data.
Content:
- Datasets
- The concept of the dipeptide and the weight
- IGA

For the prediction of our peptides, we integrated Scoring Card Method and modified to our antifungal peptide prediction system. The major advantage of the method is its simplicity, interpretability, and acceptable accuracy.
SCM, based on Support Vector Machine (SVM), is a method originating from our instructor Shinn-Ying Ho. To measure the property of anti-fungus, we introduced SCM into our model to evaluate peptides’ antifungal functions with the perspective of biological information.
- Datasets:
We obtain our positive data from antifungal databases, such as cAMP, PhytAMP and papers we found in PubMed. We collected our negative data from peptides that are not annotated to be antifungal in Uniprot.
We created the train dataset and test dataset by reducing the sequence identity of positive data and negative data to <= 25% and divide them into two portion that each dataset has equal amount of positive and negative data.
- Dipeptide:
The premise of this method is to hypothesize the function of peptides corresponding to their sequences. We viewed two amino acids as a group to form the smallest functional unit, defined dipeptides. Each dipeptide might has different propensity to make a peptide antifungal.

A peptide that has higher ratio of potentially antifungal dipeptides will more likely to be an antifungal peptide, and vise versa. The propensity of each dipeptide will be converted to a weight score (dipeptide propensity score).
- Dipeptide Frequency & Score:
Each dipeptide frequency (400 types) of a peptide refers to the ratio of the number of each dipeptide to the total dipeptides.

The score is obtained by summing each dipeptide frequency of the peptide multiplies their corresponding weight.
- Weight:
The value of weight floats every round in the computing loop. The initial weight value for each dipeptide is the ratio of the dipeptide appearing in the positive datasets minus the ratio appearing in the negative datasets. Others to be the candidates in the IGA round are picked randomly.
- Selection of Weight: Pick up Method:
We picked up two weights among all: the one that had the highest fitness value and the one selected by the Roulette method.
R is the value of Pearson's correlation coefficient (R-value) between the initial and the optimized propensity scores.
- AUC:
The Area Under ROC curves which is viewed as a way to evaluate the model built. The closer to 1 of the value is, the higher accuracy of the prediction model has.
- Roulette:
A choosing method to ensure the randomness even the higher fitness probably will be selected.
- IGA (intelligent genetic algorithm):
Cross Over Selection: A pair of parameters of the two weights are radomly choosed to exchange.
Optimization (developed by Shinn-Ying Ho): A creative method for large parameters optimization which the selection function has been designed to simplify the numbers of different parameter sets.
(For the algorithm in detail, please check out Peptide Prediction Model.)

Antifungal Database
In order to organize present antifungal data to a level of both high quantity and quality, we aggregated relative databases online and organized them to become a complete, useful and the largest antifungal database online.
Content:
- Connection of data: Hosts - Pathogens - Peptides
- Cross-match: Drug repurposing by the integration of databases
After we finished our prediction system, the next would be the integration of antifungal databases. There're several databases related to fungal infection in the internet yet lack of arrangement and integrity. The disorder of data would lead to the inconvenience for searching full information and end up to have the narrow- sighted absorbance of knowledge.
As a result, we planned to aggregate and organize all the relative data in different websites or databases to set up a complete antifungal database, reaching drug repurposing by cross-reference.
1. Connection of data
To focus on the problem we were dealing with, the fungal diseases in agriculture, there’re some factors related to the issue: hosts, pathogens, and antifungal peptides. Here's the data quantity we collected:
(1) hosts - pathogens : 514 (Phytopath / PHIbase)
(2) pathogens - peptides : 1277 (cAMP / PhytAMP)
(3) pathogens - peptides : 57 (paper searching)
By our processing, we have updated almost 300 peptides and found almost 70 new antifungal peptides.
2. Cross-match
After the data has been ordered and assembled by us, the quantity of data is even bigger than the original amounts of data before they gathered because of cross-reference. We call it the cross-match of data.

In the end, we set up our Parabase website, presenting the antifungal prediction system and validated antifungal peptides relative data relationships. Please check out the final presentation in Demonstration.
Results
- You can click here to view the demonstration - Parabase Website.
Here show the results of the peptide prediction.
For the antifungal database: the data amount we have collected
For the antifungal scoring system :
- The ROC curve and the results of test data
- Visualized antifungal scoring card
- Discussion of the relationships of dipeptides and active sites
For the achievement: the conclusion of what we’ve dedicated to humans
1.Antifungal Database (relative antifungal data)
(1)514 interactions between hosts and pathogens
(2)1334 experimentally validated antifungal peptides and their introductions
2.Antifungal Peptide Prediction System:
(1)The final ROC curve and the result of test datasets
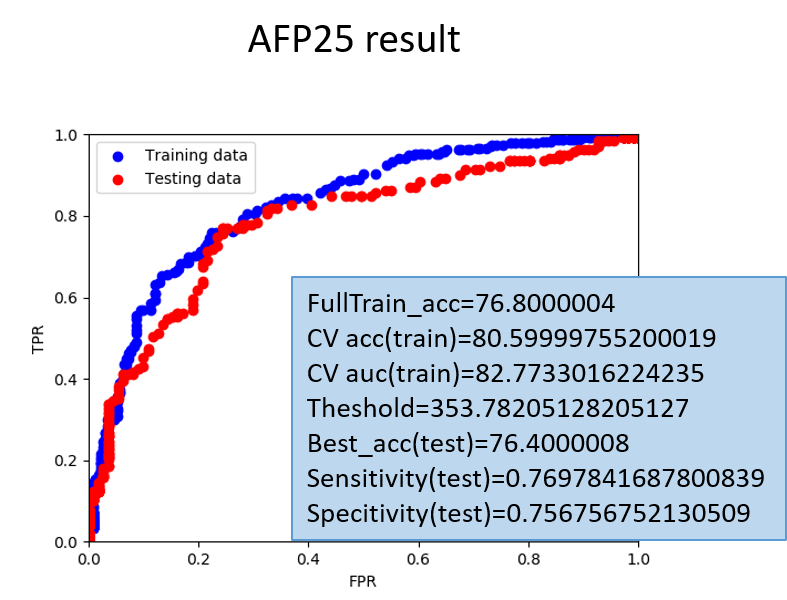
Figure 1:
The test accuracy, the overall performance of classifying positive data as positive and negative data as negative, is 76%. The sensitivity, the performance of classifying positive data as positive, is 77%. The specitivity,
the performance of classifying negative data as negative, is 76%. The suitable threshold value is 354, peptides score higher than this value is considered as antifungal peptide.
(2)The score distribution between positive datasets and negative datasets

Figure 2:
(3)Final antifungal scoring card (dipeptide score)

Figure 3:
3.Discussion

Figure 4: The bar graph above showed the single amino acid score calculated from each dipeptide score.
- Single Peptide Score Analysis:
By the score results, the top three amino acids are Cysteine(C), Glycine(G), and Lysine(K), and the five amino acids to have lowest scores are Aspartic acid(D), Glutamic acid(E), Serine(S), Threonine(T), Valine(V).
We interpreted the results as the following reasons:
There are many antifungal peptides for plants and mammals that contain lots of Cysteine , such as Thionins, plant defensins, and more. For Glycine, there are also many Glycine-rich peptides from Insect's antifungal peptides.
For the 5 peptides(D, E, S, T, V. ) of the lowest scores, four of them are hydrophilic, while most of the hydrophilic amino acids have a higher score (average score : 362.73 > threshold : 350).
Additionally, for the top 5 highest amino acids,Cysteine contains a sulfide functional group that can form disulfide bond, and Lysine(K) and Arginine(R) are easy to form hydrogen bond.
- 3D structure and active site:
To show the result of the scoring card, we visualized the peptides by drawing the dipeptide score on the peptide 3D structure. The region of a peptide become redder when the dipeptide score there is higher. Otherwise, the region become bluer when the dipeptide score there is lower.
By doing so , we can find the important region of an antifungal peptide.
We took Rs-AFP2 as an example. Rs-AFP2 was an antifungal peptide from the plant defensin family .

Figure 5:
It seemed that the N term of the peptide and the 2sheet were the reddest. To our antifungal peptide prediction system based on the SCM, it indicated that these two regions were important regions that determined the full peptide sequence as an antifungal peptide or not.

Figure 6:
To compare with papers, the paper showed that the active site are the β2−β3 loop, from Ala31 to Phe49, and some activities were found in the N-terminal part of the protein.
Comparing with the scoring card visualized picture and the real active site, we can find in the picture of score card the 3sheet and the N-terminal were also labeled.
In conclusion, we can say that SCM might possess the ability to show antifungal active sites.
Achievement
We created a powerful database that helps iGEMers who aims to solve agricultural problems caused by fungus or even other disease cases by the framework. Our database has a convenient searching tool that can quickly find out effective antifungal peptides by searching host species or fungal pathogens. Our database also enables users to find out potential new antifungal peptides by applying the antifungal prediction system.
Reference
[1]W. M. M. Schaaper,Synthetic peptides derived from the β2−β3 loop of Raphanus sativus antifungal protein 2 that mimic the active site, http://onlinelibrary.wiley.com/doi/10.1034/j.1399-3011.2001.00842.x/full, 2001